

The digitization of banking transformed how we handle money - from waiting days for cheque deposits to instant transfers. But with this digital revolution came a new challenge: processing the enormous volume of financial data flowing through modern organizations. While digital banking solved the speed problem, it created a data standardization nightmare. Every bank has its own statement format, making it incredibly difficult for businesses to process statements at scale.
Picture this: You're building a platform that needs to process bank statements from hundreds of different banks. Each bank has its own unique way of structuring data, including:
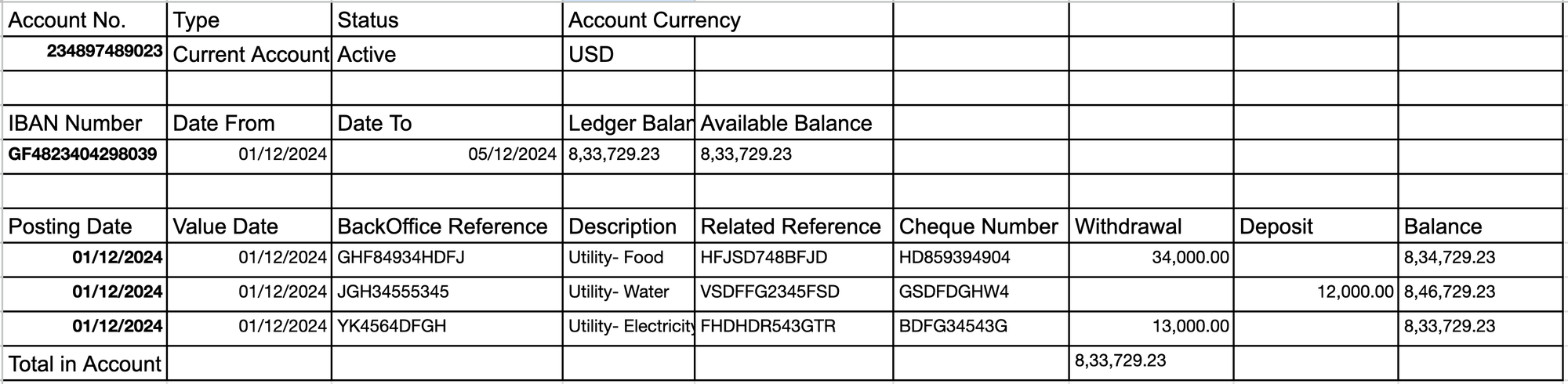

Traditionally, handling these variations required:
We tackled this challenge by building an AI-powered transformation system that can automatically analyze and standardize any bank statement format. Here's how it works:
Our system operates in three main phases:
Bank statements come in countless formats - different layouts, languages, and structures. Here's how we built an AI pipeline to handle this complexity:
1. Smart Region Detection
Instead of strict rules or templates, we use an island detection algorithm to find the main transaction table. This first detects all the tables in the entire file and returns the largest table as a pandas dataframe:
def detect_largest_island(df: pd.DataFrame) -> Tuple[str, pd.DataFrame]:
"""Find the largest coherent data region while ignoring noise."""
# First, we look for empty rows to identify potential data boundaries
empty_rows = df.isna().all(axis=1)
# Then find the largest contiguous block of populated cells
largest_island = find_max_data_region(df, empty_rows)
return largest_island.region, largest_island.data
2. Intelligent Field Mapping
We use the table from the island detection algorithm to prompt an LLM, enabling us to infer the intent of each column and later rename them to match our internal format. This is the intelligent step empowers us to handle any bank statement globally without needing custom code:
def get_column_mappings(df: pd.DataFrame, column_info: Dict) -> Dict[str, Any]:
"""Map variant column names to standard fields."""
# Send column names and sample data to Claude
response = claude.analyze(
column_info=column_info,
sample_data=df.head(10)
)
# Get standardized mappings (e.g., "Credit" = "Inflow" = "دائن")
return response.mapped_columns
3. Dynamic Transformation Engine
Finally, we convert everything to standard formats:
def transform(df: pd.DataFrame, template_config: Dict) -> pd.DataFrame:
"""Transform data based on detected patterns."""
# Extract columns using the mapping
result = extract_columns(df, template_config)
# Add any required metadata
result = add_attributes(result, template_config)
return result
When processing bank statements, one of the trickiest challenges is identifying where the actual transaction data lives. Bank statements are essentially a maze of headers, metadata, transaction rows, and empty spaces. Here's how we solve this using our "Island Detection" algorithm.
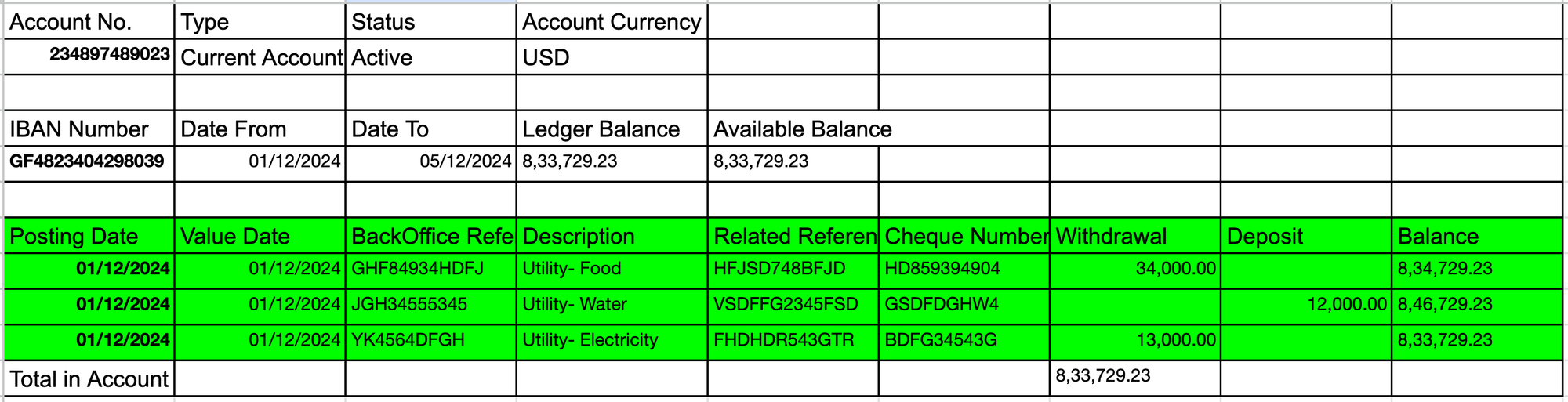
The Core Challenge: Locating Data Islands
Let's start with a real example. Consider this statement with both Arabic and English headers, scattered data, and regular blank rows:
bتاريخ التسجيل | مدين | دائن | الرصيد
Posted Date | Debit| Credit| Balance
01/10/2023 | 300 | | 1,34,13,442.89
[blank row]
01/10/2023 | 300 | | 1,34,13,442.89
To make sense of this, we need to:
def detect_largest_island(df: pd.DataFrame, start_row: int = 0) -> Tuple[str, pd.DataFrame, int]:
"""
Find the largest rectangular block of non-empty cells.
Key Steps:
1. Find all empty rows (our "water")
2. Between each pair of empty rows:
- Find non-empty columns
- Calculate area (rows × columns)
- Track the largest area found
3. Return the largest block's coordinates and data
"""
start_row = start_row - 1
df_slice = df.iloc[start_row:]
# Find rows that are completely empty
empty_rows = df_slice.isna().all(axis=1)
empty_row_indices = empty_rows[empty_rows].index.tolist()
# Handle case with no empty rows
if not empty_row_indices:
empty_row_indices = [len(df_slice)]
largest_island_size = 0
largest_island_region = ""
largest_island_df = None
# Scan between empty rows for islands
island_start = 0
for end_row in empty_row_indices:
if end_row > island_start:
# Get the current island slice
island_slice = df_slice.iloc[island_start:end_row]
# Find columns containing any data
non_empty_cols = island_slice.notna().any()
if non_empty_cols.any():
# Get the start and end columns of this island
non_empty_col_indices = non_empty_cols[non_empty_cols].index
start_col = non_empty_col_indices[0]
end_col = non_empty_col_indices[-1]
# Calculate area in cells
island_size = (end_row - island_start) * (end_col - start_col + 1)
# Update if this is the largest island found
if island_size > largest_island_size:
largest_island_size = island_size
largest_island_region = (
f"{col_num_to_letter(start_col + 1)}{start_row + island_start}:"
f"{col_num_to_letter(end_col + 1)}{start_row + end_row -1}"
)
largest_island_df = island_slice.iloc[:, start_col:end_col+1]
island_start = end_row + 1 - start_row
return largest_island_region, largest_island_df
# Convert a column number to Excel-style letters using base-26.
def col_num_to_letter(col_num: int) -> str:
"""
Example:
28 -> "AB" works like this:
28-1 = 27
27 % 26 = 1 (B)
27 // 26 = 1
1-1 = 0
0 % 26 = 0 (A)
Result: AB
"""
col_num -= 1
letters = []
while col_num >= 0:
letters.append(chr(65 + (col_num % 26))) # Convert to A-Z
col_num = (col_num // 26) - 1 # Move to next digit
return ''.join(reversed(letters)) # Reverse to get correct orderIsland detection
How It Works in Practice
The algorithm moves through the document systematically:
Edge Cases and Optimizations
Our algorithm handles several edge cases elegantly: when a document has no empty rows, it's treated as a single potential island; columns must contain at least one non-empty cell to be included (preventing empty blocks from skewing our calculations); and all islands must have positive size to be considered.
This combination of techniques gives us robust table detection that works across different bank statement formats, languages, and layouts. The largest contiguous block of data is almost always our main transaction table, making this a reliable first step in our parsing pipeline.
After finding our data island, we use Claude to understand what each column means. Bank statements use different terms ("Credit" vs "Inflow"), split fields ("Amount" into credit and debit), and mix languages (Arabic/Polish/English). Here's how we standardize this:
def get_column_mappings(island_df: pd.DataFrame, column_info: Dict[str, Any]) -> Dict[str, Any]:
"""Map variant column names to standardized fields using LLM analysis."""
try:
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Convert data for LLM input
column_mapping = json.dumps(column_info, indent=2)
csv_buffer = io.StringIO()
island_df.head(10).to_csv(csv_buffer, index=False, header=None)
sample_data = csv_buffer.getvalue()
# Core prompt for the LLM
llm_message = f"""
You are a financial analyst, mapping bank statement data to a standardized format.
The accepted format is:
<accepted_format>
{ACCEPTED_FORMAT} # Contains fields like transaction_date, value_date, debit, credit etc.
</accepted_format>
Analyze these inputs:
1. Column Mapping: Column definitions from the bank statement
2. Sample Data: First few rows to understand the data format
Your task:
1. Map each input column to the standard format
2. Handle similar names (Credit/Inflow)
3. Deal with split fields (dates in multiple columns)
4. Manage multilingual content (Arabic/English)
5. Note any unmapped fields or errors
Return a JSON with:
- mapped_columns: Array of {{"name", "type", "region", "mapped_attribute"}}
- unmapped_attributes: Fields we couldn't map
- errors: Any issues found
Example mapping:
Input column: "تاريخ التسجيل" (Registration Date)
{
"name": "تاريخ التسجيل",
"type": "date",
"region": "A1:A10",
"mapped_attribute": "transaction_date"
}
"""
# Get LLM's interpretation
message = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=3000,
temperature=0,
system=llm_message,
messages=[{
"role": "user",
"content": [{
"type": "text",
"text": f"""
Input:
<column_mapping>{column_mapping}</column_mapping>
<sample_data>{sample_data}</sample_data>
"""
}]
}]
)
# Parse and validate response
response = json.loads(message.content[0].text)
return extract_and_validate_llm_response(response)
except Exception as e:
print(f"Error: {str(e)}")
return [], [], []
How It Works
{
"mapped_columns": [
{
"name": "Posted Date",
"type": "date",
"region": "A1:A10",
"mapped_attribute": "transaction_date"
}
],
"unmapped_attributes": ["value_date"],
"errors": ["Inconsistent date format in column A"]
}
The LLM approach gives us flexibility to handle new statement formats without hardcoding rules for each bank's specific format. For any unmapped required attributes, we make another LLM call to scan the non-island regions (headers, footers, metadata sections) of the document. When found, these attributes are added to our contract as additional attributes:
{
"type": "add_attributes",
"config": {
"additional_attributes": [
{
"name": "account_number",
"value": "234897489023",
"region": "B2:B2" # Found in header
},
{
"name": "currency_code",
"value": "USD",
"region": "D1:D1" # Found in metadata
}
]
}
}
This two-pass approach ensures we capture all required information, even when it's scattered across different parts of the document.
After mapping columns, we need to transform the data into a consistent format. Bank statements show dates, numbers, and currencies in various ways - our engine handles this automatically.
The Transformation Pipeline
We use a configuration-driven approach to transform data:
class ColumnMapping(BaseModel):
"""Defines how to map a source column to our standard format"""
name: str # Original column name
type: str # Source data type
region: str # Excel-style location (e.g., "A1:A10")
mapped_attribute: str # Target field name
attribute_type: str # Target data type
def transform(df: pd.DataFrame, template_config: Dict[str, Any]) -> pd.DataFrame:
"""
Transforms bank statement data based on configuration rules.
Handles multiple actions like column extraction and attribute addition.
"""
try:
original_df = df.copy()
result_dfs = []
for action in template_config["actions"]:
action_type = action.get("type")
if action_type == "extract_columns":
result_dfs.append(extract_columns(original_df, action.config))
elif action_type == "add_attributes":
result_dfs.append(add_attributes(original_df, action.config))
return pd.concat(result_dfs, axis=1)
except Exception as e:
raise Exception(f"Transform error: {str(e)}")
Smart Data Type Handling
We handle various data formats through specialized transformers:
def transform_float(value):
"""
Converts various number formats to standard floats:
- Removes currency symbols and commas
- Handles negative values
- Converts strings to numbers
"""
if isinstance(value, str):
cleaned = re.sub(r'[^\d.]', '', value)
return abs(float(cleaned))
return abs(value) if isinstance(value, (int, float)) else None
def transform_date(value):
"""
Standardizes date formats to ISO:
- Handles various input formats
- Converts to UTC timezone
- Outputs in ISO format
"""
try:
dt = parser.parse(value, fuzzy=True)
dt = dt.replace(tzinfo=timezone.utc)
return dt.strftime('%Y-%m-%dT%H:%M:%SZ')
except ValueError:
return None
Example Transformation
Here's how it works with real data:
# Input Configuration
config = {
"type": "extract_columns",
"config": {
"column_mappings": [
{
"name": "Posting Date",
"type": "date",
"region": "A7:A10",
"mapped_attribute": "updated_date",
"attribute_type": "date"
},
{
"name": "Balance",
"type": "number",
"region": "I7:I10",
"mapped_attribute": "balance",
"attribute_type": "float"
}
]
}
}
# Input Data (Sample)
"01/10/2023" -> "2023-10-01T00:00:00Z"
"1,34,13,442.89" -> 13413442.89
The engine:
Added Attributes
We can also inject constants and computed fields:
# Adding account metadata
{
"type": "add_attributes",
"config": {
"additional_attributes": [
{
"name": "account_number",
"value": "234897489023"
},
{
"name": "currency_code",
"value": "USD"
}
]
}
}
This configuration-driven approach lets us handle new bank statement formats by just updating the configuration, without changing the code.
The implementation of this AI-powered system has delivered remarkable improvements:
The success of this project taught us several valuable lessons:
The AI revolution isn't about replacing human effort—it's about amplifying our ability to solve problems at an unprecedented scale. By transforming a manual, error-prone process into an automated, adaptive system, we've made bank statement processing seamless and reliable, no matter the complexity.
And this is just the beginning. As we continue to refine and expand our agentic system, we're paving the way for a future where financial automation is not only intelligent but transformative. We're excited to share the journey ahead, full of breakthroughs and innovations that will redefine what's possible